Creating Standard pipeline
-
On the DataGOL Home page, from the left navigation panel, click Lakehouse > Pipelines.
-
In the Pipelines page, from the upper right corner, click + New Pipeline button.
-
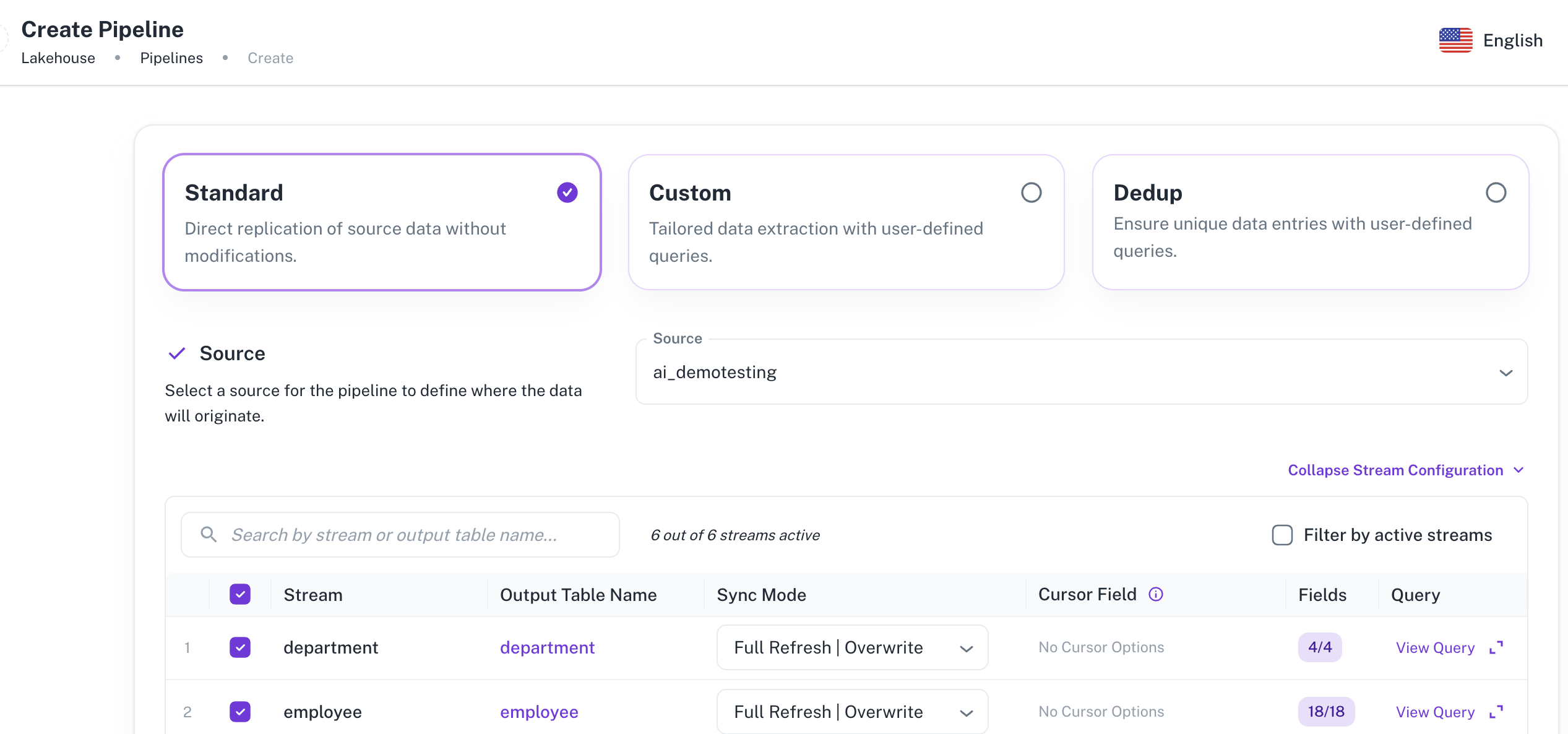
Select Standard to directly replicate the source data without modifications.
-
From the Source drop-down list, select a source for the pipeline to define where the data will originate. The streams corresponding to the selected source are listed.
-
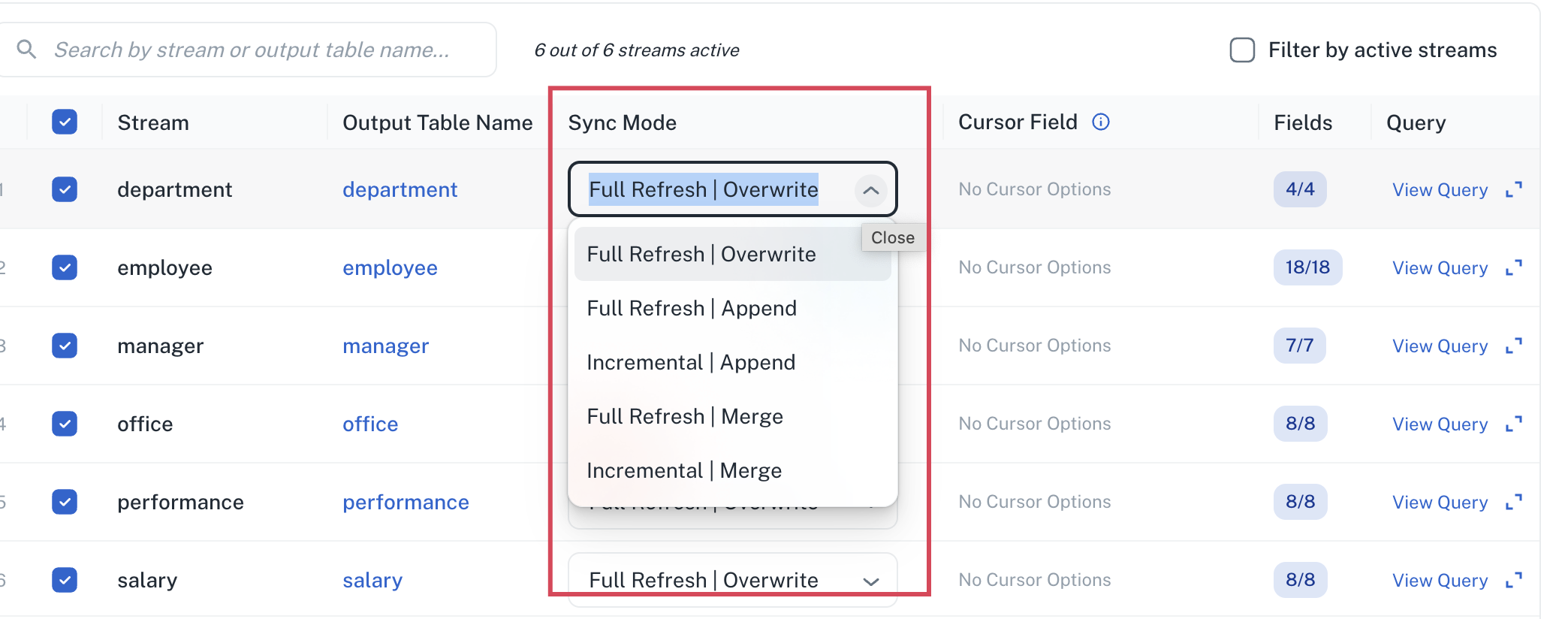
From the Sync mode column, set the sync mode for the streams. Refer Sync modes for more information.
-
In case of incremental operations that is Incremental|Append and Incremental|Merge operations, you must select a cursor field from one of the following options.
-
id (bigint)
-
from_date (date)
-
to_date (number, date)
-
last_updated (timestamp)
For incremental appends, the cursor field must follow a strict, predictable order, which is always increasing.
DataGOL does not support decreasing modes for now.
-
-
From the Destination drop-down, select a destination for the pipeline to specify where the processed data will be delivered. You can also select the + New Warehouse button to create a new destination for the pipeline.

You can choose either Iceberg or Parquet format while creating the new warehouse. Iceberg tracks changes to data, creating a change set. This allows users to query data based on specific versions and understand the changes. Iceberg ensures that only changes are reflected, avoiding duplicates.
Apache Iceberg format is supported for data ingestion from MySQL, MS SQL Server, and PostgreSQL, and data delivery to S3. Currently, Iceberg sync modes that is Incremental|merge and Fullrefresh|Merge are supported in standard pipelines.
-
From the Settings drop-down, customize the pipeline parameters specifically for your needs.
-
The Format field is populated with the format that is selected for the source.
-
If your source is in Parquet format, the destination is also in Parquet format.
-
If your source is in Iceberg format, the destination is also Iceberg format.
-
-
Choose the query engine to execute the data transformations and processing within your pipeline. This can be either Spark or Athena. Athena can be used when source and destination both are S3 warehouses. You must specify the query engine while creating a pipeline. After the pipeline is created you cannot change the query engine.
-
The frequency at which a data pipeline runs is determined by the chosen replication method. This dictates how and when the system executes the pipeline to replicate data. There are a few key methods:
-
Manual (On-Demand): With this method, the pipeline only runs when a user explicitly initiates it. It requires manual intervention each time data replication is needed. If no manual trigger occurs, the pipeline remains inactive.
-
Cron: This method allows for highly specific scheduling using cron expressions. You can define precise times, days of the week, and even specific minutes or seconds for the pipeline to run automatically. For example, a cron expression could be set to run the pipeline in a week or first of every month.
-
Scheduled: This method offers predefined intervals for automatic pipeline execution. Users can typically select options like running the pipeline every hour, every 3 hours, daily, weekly, monthly, or yearly. Once a schedule is set and submitted, the pipeline will automatically run at the specified frequency, regardless of the system's status at that exact moment.
-
-
-
Click Submit.
When a standard pipeline is created, a parent pipeline is generated along with child pipelines for each selected stream for all data sources except REST data sources (third party applications e.g hubspot, amplify etc). This enables synchronization of individual tables/streams.